在前面的月度复盘中,充斥着大量的图片,因为我认为视觉效果能最直接地唤起图片里的那段回忆。但另一面的缺点也十分显著,就像是小朋友的流水账,缺少思考。又或者说,我因为逃避思考而用这般方式取而代之。
我也并不需要记住所有这些闪耀或暗淡的时刻,那些深刻或不便公开的时刻也无须被这般记录。所以在一月份结束后,我没有接着记录自己无所谓的日常,当然这兴许也有一半归功于这段时间繁多的学习及项目开发。
在过去的两个月里,我于网络和现实的反馈中学到许多想与你们分享的内容。有关生活,有关人性,有关技术,有关禅意,也有关爱。当然重要的收获之一是,我开始行想合一。反抗自己内心中行动的侏儒,且取得些许战果。
由心
从前,我用我的眼睛去观察这个世界,用我的身体去丈量万物。由我,不由心。
某一刻,我突然开始用心去体会这个世界,我慢慢学着放松,慢慢深呼吸。似乎心就是深呼吸后的不紧不慢;不张不弛;不喜不悲;不善不恶;不怨不嗔;不贪不恋;不惧不畏;直下承当。
现在的我,就是我的心。
祂不会批判任何人,任何人所做的一切都是为了寻求一种安全感。行为的背后是其童年,是其社会情感,是其目的,是可以逻辑去解读的。
无论是内心深处的虚伪,外表光鲜的假相,还是如此种种。皆是对自我的保护,保护自己何错之有?不过以这般别扭的方式,不免也怪可爱。
最近无意看见空一师的《稍安》,这些诗文不是心灵鸡汤的油腻,也没有文人矫情造作。像是在番茄菌子汤中烫些山间的野菜吃,其味清淡,回味却远长。




情感洁癖
在今年一月初,因一好友的倾诉而讨论到情感洁癖。当时有写过一篇文章,但内容较乱且自觉未能清楚表达,故将其隐藏。
只有在在双方共同探索深度联结之后,我们内心的小孩才可能“撒娇”提出一些要求。当人越在意什么的时候,越希望它是美好的,也越渴望维持延续它的美好。同时,对感情的理想主义会让我们认为:双方总愿意互相理解、互相沟通、能够共同为关系的持久而努力、共同在一段健康的关系中携手成长。
可现实中不少关系却往往是别扭的沟通方式和难以控制的情绪的组合,一个平日理智的人真正陷入一段亲密关系中时,往往会亲自将自己灌醉。
以解决这类问题,吐露不失为很好的办法。不攻击、不回避,真诚地吐露你的担忧并不会让你处于被动地位,反而能够促进情绪流动。
Solitude
我很喜欢用 Solitude, Alienation, Unique 这类单词来形容自己,以至于买了不少和其相关的域名 solitude.land, alienat.io, unique.quest。
因为我认为这个世界是由孤独所驱动的,孤独是一个人的清欢。这种孤独并非狭义的与世隔绝,而是一种精神上的独立。只有在这种状态中,才能向内探索自我审视,发现内心真正的需求。
阿德勒在《自卑与超越》中指出:人生所面临的所有困难或问题,都源自于在生活中受到的三大制约。其二则是我们每个人都必须与周围其他人相互关联,任何人都是人类体系中的唯一成员。一个人无法单独达成目标,这是由人类个体的弱点和局限所决定的。一个人如果独自孤单地生活,自己面对一切,最终只会走向灭亡。
在第一次读到这段话时,内心难免有些抵触。一直以来我很少借助他人的帮助,几乎所有事情都想依靠自己解决。一方面,可能是完美主义的原因让我不放心他人;另一方面,可能是原生家庭和一些经历让我对合作共事毫不在乎。
可随着这条路继续往里走,事实又并非如此。我有许多与他人的联结在背地里悄然发生,回头望去才发现自己结交过“千奇百怪”的朋友,以至于左右逢源。同时,我也没少与他人合作以共同求索,只是共事的场景多数发生在网络中,才得以让这类相关经历从大脑的浅层联想中逃逸。
这种波动有些类似于我九型人格中核心人格的健康状态的起伏:
当第五型健康时,他们会成为其感兴趣领域的思想先驱,并且通常被认为是社会智慧进步不可或缺的一部分。他们清晰而准确地看到了大而复杂的问题。通过奉献精神和真诚的好奇心,他们能够催化变革并推动社会运动。对第五型来说,不可能变成可能,他们可以带着信心提出新的发明、系统和思维方式。他们成为主题里的专家,自由地与公众分享他们的智慧和发现。凭借简化复杂事物的天赋,第五型有可能以极其清晰的方式传达以前令人难以置信的学术或话题。
当第五型处于平均水平时,他们是另类、孤僻和情感封闭的。他们可能有一些深奥的兴趣,但他们一直隐藏在公众的视线之外——并选择表现出一种冷漠和疏远的气场。他们精通自己感兴趣的话题,可能会被同行视为“书虫”。在空闲时间,第五型利用他们在脑海中创造的不同世界来逃避日常生活的平凡琐事。例如,他们可能会钻研自己收藏的大量书籍,或者喜欢玩战略棋盘或纸牌游戏来打发时间。
当第五型不健康时,他们会切断他们的整个社交世界,并可能发展出狭隘的视野。他们开始有遥远而激进的观点,失去了对现实的控制。由于缺乏情感意识和远见,第五型可能会发现自己陷入激烈的争论而没有明确的答案。结果,一些友谊可能会在此过程中被切断,这肯定会使第五型感到困惑。进一步的,他们可能会合理地认为,自己一个人会过得更好,并选择逃离现实世界。此外,他们可能会沉迷于很少有人能理解的遥远理论,固执地坚持一种智力优越感。这最终会使第五型将人们推离得更远。在最糟糕的情况下,第五型可能会变得厌世和痛苦不堪。
I'm alone but not lonely.
孔乙己
最近孔乙己文学又被广为流传,这一次人们用所谓的高学历来代表孔乙己的长衫。其意为穿过读书的长衫后便拉不下面子去做别的活,是续走不出的浪浪山后又一骨感现实的喻言。
在第一次见这个形容时我并不知道其出处,去搜索后才发现孔乙己是鲁迅先生短篇小说下的一个人物。文章很短,所以我立即去读完了原文。其实不应管其篇幅如何都应该去研其出处,我所言的篇幅短才去读是因为最近有不少事情等着我处理。想表达的意思是,虽然各大媒体上皆有讨论,但人们在看待一件事物的时候难免不参杂自己主观意愿,更别提那些本就擅长利用群体心理学歪曲事实以提高传播和影响力的媒体。在这般环境下若失去溯源的思想,又怎能窥见其背后的真相呢。
例如知乎宇宙中著名的《假如一个初中生发明了百草枯的解药,能不能保送清华北大哈佛?》,少部分人揣着明白抖机灵,大部分人却真的以为百草枯沾了必死,特别是众多媒体号都在渲染其如何痛苦死去的过程。然而事实是早在2000年左右便有文献及临床实践证实百草枯中毒是可以治疗的,如《百草枯中毒救治“齐鲁方案”(2014)》中提到的数据:近 3 年救治病人总数 983 例,临床治愈 649 例,治愈率达到 66% 。
回到孔乙己,结合当时时代背景能很明显看出来,其长衫不代指某个人也不代指某个群体,而是当时封建社会下即将被淘汰的科举制度礼教文化等等。而把长衫比作学历,无疑是把自己嵌定在固定式思维里。换句话说,随着中国高等教育普及和资源增长,曾经的终点变为了现在的起点,21世纪的硕士报考人数逐年递增也印证了这一点。
鲁迅先生最厉害的地方,就是将中国人的人性中最普遍的性质抽象出来,并化为书中具体的人物。于是哪怕过了一百年,鲁迅先生书中的人物依然让人心有戚戚。文中的孔乙己是悲剧的,而咸亨酒馆中的那些看客们,以及柜台的“我”,才是更大的悲剧。我们其实都是时代巨轮下的蝼蚁,可怜的是蝼蚁也有鄙视链。孔乙己作为蝼蚁中的异类,饱受了党同伐异的苦。
相比孔乙己在封建文化下的迂腐,我更多看见的是他的善良与单纯。在整个鲁镇都是边缘人物的他,受大家歧视,被疏远被排斥,不被任何人理解,日子过得孤独无助的他,却在教“我”识字那一段中还能显露出其真诚美好的品质,实在难能可贵。
孔乙己自己知道不能和他们谈天,便只好向孩子说话。有一回对我说道,“你读过书么?”
我略略点一点头。
他说,“读过书,……我便考你一考。茴香豆的茴字,怎样写的?”
我想,讨饭一样的人,也配考我么?便回过脸去,不再理会。
孔乙己等了许久,很恳切地说道,“不能写罢?……我教给你,记着!这些字应该记着。将来做掌柜的时候,写账要用。”
我暗想我和掌柜的等级还很远呢,而且我们掌柜也从不将茴香豆上账;又好笑,又不耐烦,懒懒地答他道,“谁要你教,不是草头底下一个来回的回字么?”
孔乙己显出极高兴的样子,将两个指头的长指甲敲着柜台,点头说,“对呀对呀!……回字有四样写法,你知道么?”
我愈不耐烦了,努着嘴走远。
孔乙己刚用指甲蘸了酒,想在柜上写字,见我毫不热心,便又叹一口气,显出极惋惜的样子。
在这里引用知乎用户 @汤咸祖 的一段书评:
孔乙己先是试探性的问了问,“你读过书吗”?若是“我”不点头,孔乙己断然也不会强行推销自己观点的。正是因为“我”点头了,孔乙己认为终于有一个人跟自己有点儿共同语言了。满脑子之乎者也的孔乙己,也只能在这事儿上与人唠唠嗑。赵家的老爷和乡里的秀才看不上他,酒馆里无论是穿长衫的还是穿短衫的都歧视他,在这样的情形下,“我”哪怕是一个帮工的孩子,读过书,能识字,也显得弥足珍贵。因为“我”有可能成为孔乙己的知音。
接下来,孔乙己想到的是“我记账要用”,这里可以看出孔乙己的善良。他的的确确是在为“我”考虑,而非完全的自说自话。
最值得注意的是,是孔乙己的语气是“恳切”的。许多读者认为孔乙己迂腐得不可救药,考问“我”茴香豆的写法,不过是在炫耀自己微不足道的才学。但若真是炫耀,语气可以是“得意”的,但断不可能是“恳切”的。孔乙己是真正的把自己和“我”放在了一个平等交流的位置,而不是居高临下的好为人师。
另一个值得注意的点在于,当“我”回答出了孔乙己的问题时,孔乙己表现出“极其高兴的样子”。若是好为人师,往往巴不得别人回答不了自己的问题,才好卖弄才学。而孔乙己却是极其高兴的,他高兴的点在于终于有一个人能够交流了,干瘠皲裂的内心,因为“我”的回答,又萌发了生机。
最后,孔乙己见“我”毫不热心,表现出的是“惋惜的样子”。他为什么的惋惜,仔细思考下来,也着实让人心酸。一个没有朋友的边缘人物,好不容易找到一个可能交谈的人,却一瞬间又失去了。没有什么比在绝望中看见一点光芒,还没有看清楚光芒的样子,光芒就刹那消散更让人难受的事了。
可见,孔乙己也是一个可怜可悲又善良的人。
相比把仅是现代社会就业的基础学历比作长衫,还不如将中国的应试教育比作长衫。不过近年来国家也开始改进这方面的问题,开始大力扶持职业教育。反倒是那些不愿延迟满足的,在奶嘴乐中固步自封的,所谓的大学生,过得憋屈、拧巴,清醒又迷茫,还不如孔乙己呢。
犹怜草木青。
# Dev
再说说这两个月在开发上的舍与得。
在一月初的时候,研究了数字媒体频域水印,通俗来说就是图片隐写术。关于具体的技术细节可见知乎问题"阿里巴巴公司根据截图查到泄露信息的具体员工的技术是什么?"下用户记忆张量的回答,而相关技术实例可见用户猫咪他大爷的回答。不过在这方面的进展因后续的其他事情而搁置,部分内容可见文章草稿隐写术:逮出在朋友圈盗图的人。
随后在安卓逆向工程方面也略有所染,虽然前期挺顺利,但由于是 QT Quick 打包的应用,最后还是卡在了 so 文件(二进制)逆向。
再往后就是时隔多年又接触了微信小程序,但这次实在是不想再用微信那套自己的开发框架,于是转头开始尝试小程序方面多端统一开发的解决方案,最后敲定为 Taro 框架。文章被隐藏记录在:Taro 多端统一开发解决方案上手,隐藏的原因是我认为并没有任何技术创新及难度可言。
完事又开始接触人工智能,还记得读大一时在高明权老师那儿听课的日子,很涩很难懂。
虽然印象里初中拿过当时的数学年级第一,但之后的日子实在对这些高度抽象的学科提不起兴趣,故弃之。但好在这个世界仍然存在许多优质的教学内容,例如 fast.ai 的免费在线课程 Practical Deep Learning for Coders,其中一段介绍非常吸引我:
At fast.ai we care a lot about teaching. In this course, I start by showing how to use a complete, working, very usable, state-of-the-art deep learning network to solve real-world problems, using simple, expressive tools. And then we gradually dig deeper and deeper into understanding how those tools are made, and how the tools that make those tools are made, and so on… We always teach through examples. We ensure that there is a context and a purpose that you can understand intuitively, rather than starting with algebraic symbol manipulation.
似乎有点像卖课的了,那便回到我的开发成果上。在这段时间我训练了一个名为 Metor 的大型语言模型,对,和 ChatGPT 的尿性相差无几。说起来我第一次接触 ChatGPT 还是去年 12 月初,也就是其发布的第五天:
简单来说,就是基于 RLHF (Reinforcement Learning from Human Feedback) 技术来克服大型语言模型的局限性,使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。这项技术已在早先的学术研究中被提出,ChatGPT 则代表了首个将此技术用于生产模型的实例,Training language models to follow instructions with human feedback 这篇学术研究便是 OpenAI 在其模型上使用 RLHF 最相关的内容。当然这项技术也并非是完美的,训练出来的模型依然会不确定性地输出有害或者不真实的文本。
在 ChatGPT 风靡后,许多人工智能方面的组织都提供了加速训练出与 ChatGPT 类似大型语言模型的指导及代码库,以加速其已有成果转化。近几天 Meta (Facebook) 也开放了他们的大型语言模型 MetaAI (LLaMA) Introducing LLaMA: A foundational, 65-billion-parameter large language model,在 LLM 的遍地开花后,相信我们距离其背后风险与危害的彻底解决方案会越来越近。
以下是 Metor 的部分能力展示,前端为 SvelteKit,后端为 Node.js 与 Python 混合:
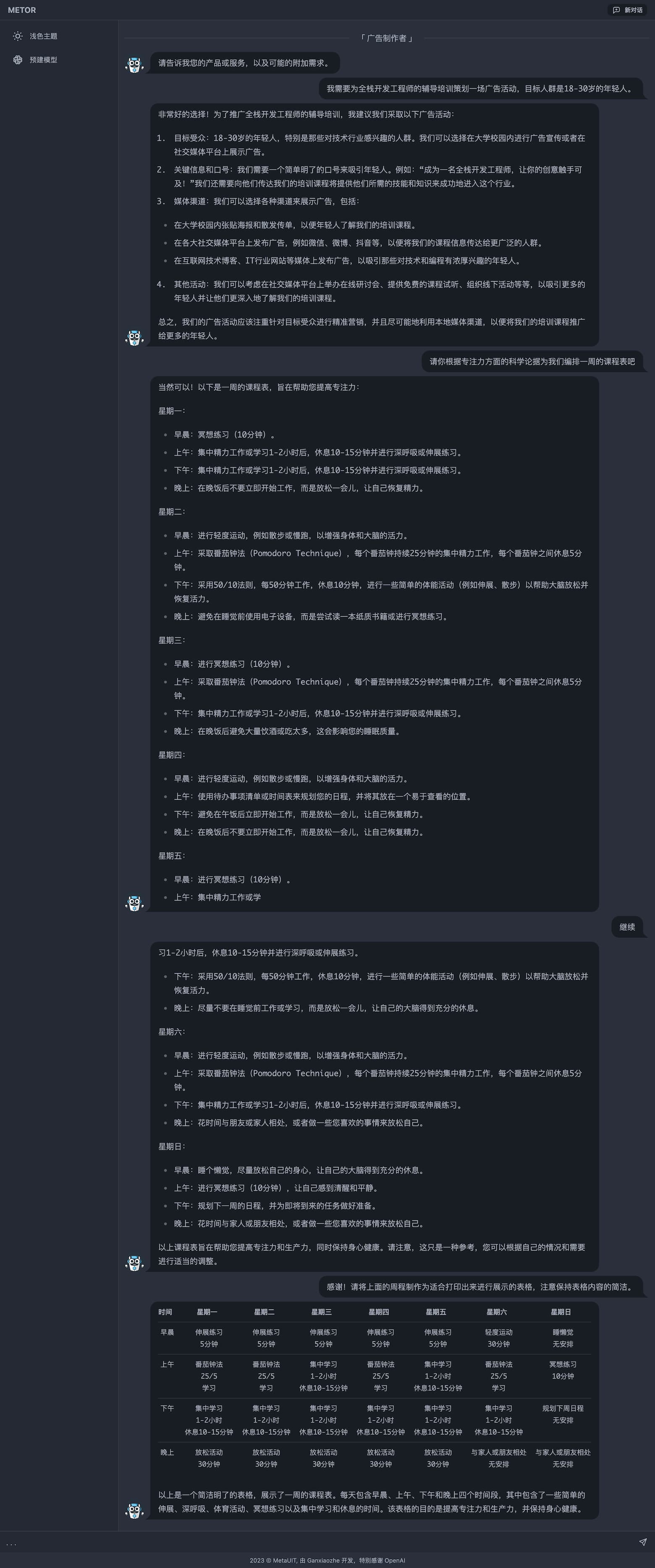
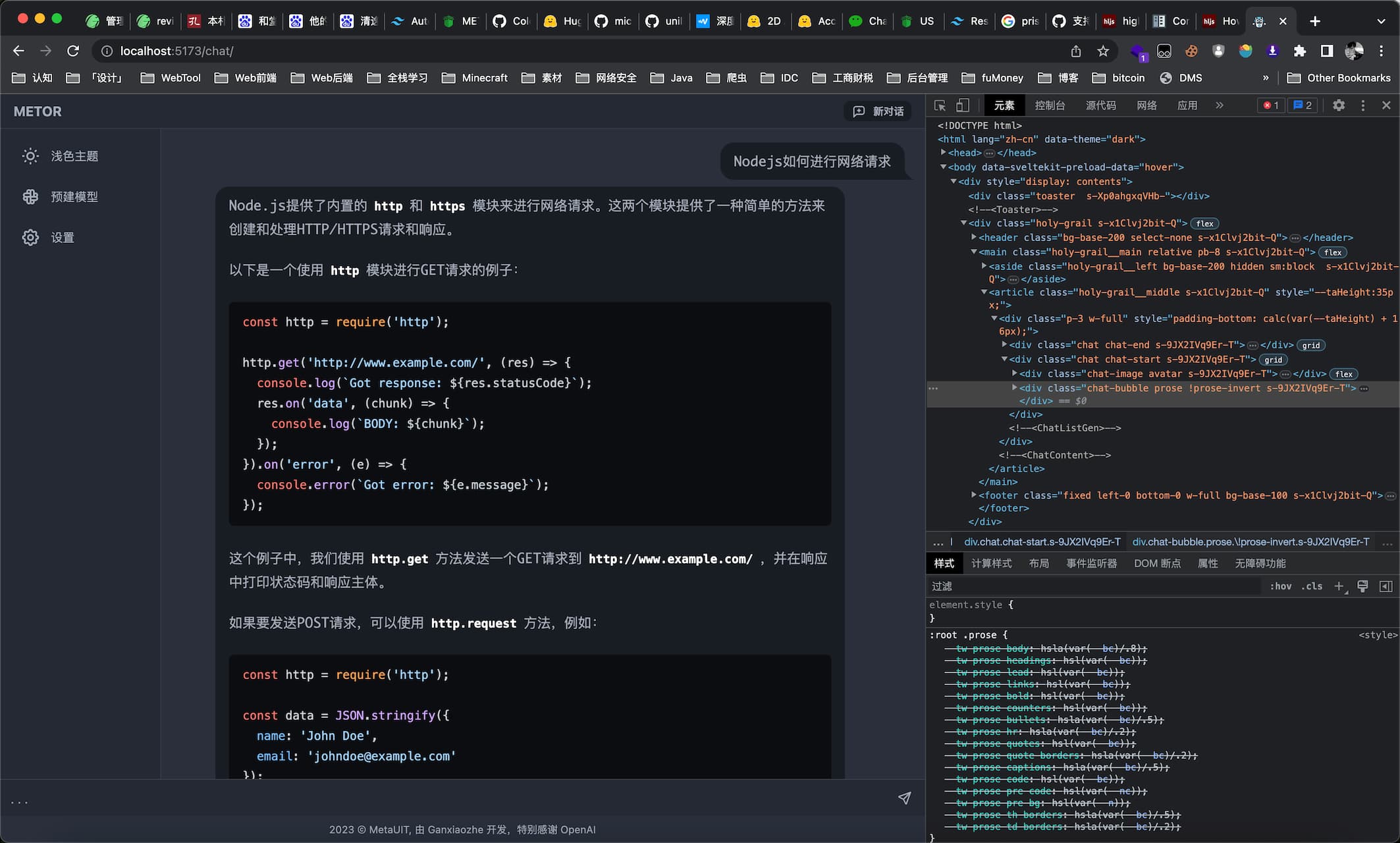
AI: LLMs
在过去的一年里,大型语言模型 (LLMs) ——具有数十亿参数的自然语言处理 (NLP) 系统已经显示出其强大的功能。在技术领域上,其主要是基于 NLP 和深度学习 (DL) 实现。
自然语言处理:NLP 是计算机科学、人工智能和语言学的交叉领域,旨在使计算机能够理解、解析和生成自然语言。大型语言模型的许多任务,如文本分类、情感分析、问答等,都属于 NLP 领域。NLP 提供了处理自然语言的基本理论和方法,为大型语言模型的实现奠定了基础。
深度学习:深度学习是一种特殊的机器学习方法,它使用多层神经网络来学习复杂的模式和特征。深度学习方法在许多领域(包括 NLP)取得了巨大成功,使得大型语言模型能够实现高效的自然语言理解和生成。深度学习技术为大型语言模型提供了强大的计算能力和表现力。
以下为 LLMs 基于这两领域的技术,实现文本生成的简要原理。
- 预处理:在训练模型之前,首先对原始文本数据进行预处理。这包括分词(将文本拆分成单词、短语或子词的过程)和编码(将每个词语转换为模型可以理解的数值表示)。
- 预训练:使用大量的无标签文本数据(如网页、书籍、新闻文章等)对模型进行预训练。预训练的主要目标是学习词汇表中每个词语的向量表示(称为词嵌入)以及文本的上下文信息。这通常通过自监督学习任务完成,如“masked language modeling”(遮蔽语言建模),其中模型需要预测句子中被遮蔽的词语。
- 微调:在预训练完成后,使用具有标签的专门数据集对模型进行微调。微调过程使模型能够根据特定任务(如文本分类、情感分析、摘要生成等)进行优化。这是一个监督学习过程,模型在训练期间会根据标签调整权重以最小化损失函数。
- 自注意力机制:Transformer 架构的核心是自注意力(self-attention)机制。它允许模型在处理序列数据时,关注输入序列中的不同位置的相关信息。自注意力机制使模型能够捕捉长距离的依赖关系,对于理解和生成自然语言文本非常重要。
- 编码器和解码器:虽然目前最先进 GPT 系列只包含解码器部分,但传统的 Transformer 架构包括编码器(将输入数据转换为固定大小的向量表示)和解码器(将编码器的输出转换为目标序列)。编码器和解码器均由多层自注意力和前馈神经网络组成,这些网络在训练过程中共享权重。
- 生成文本:在模型训练和微调完成后,可以使用模型生成文本。给定一个输入序列,模型会基于所学习的上下文信息和条件概率分布生成接下来的词语。这个过程可以通过贪婪搜索、集束搜索(beam search)或其他生成策略完成。
进一步简化后步骤如下:
- 对文本数据进行预处理(分词和编码)。
- 在大量无标签文本数据上进行预训练,学习词嵌入和上下文信息。
- 使用有标签的专门数据集对模型进行微调,以适应特定任务。
- 利用自注意力机制捕捉输入序列中的长距离依赖关系。
- 使用编码器和解码器处理输入数据和生成目标序列(完整的 Transformer 架构)。
- 生成文本时,根据条件概率分布和生成策略选择接下来的词语。
可能这样说对于那些有 CS 知识背景但又没具体接触过 AI 相关技术的朋友仍然不够具体。为此,再补充一下 NLP、DL 与 LLMs 之间的关系。在技术层面上, NLP 与 LLMs 的关系如下:
- 数据表示:NLP 技术提供了将自然语言文本转换为计算机可理解的形式的方法。例如,词嵌入(如 Word2Vec 或 GloVe)可以将单词转换为高维向量,以便计算机处理。大型语言模型则使用更先进的表示方法,如上下文相关的词嵌入(如 BERT 或 GPT),它们根据单词在文本中的上下文动态调整词向量。
- 序列建模:NLP领域的序列建模技术被广泛应用于大型语言模型。在训练过程中,模型需要学会预测给定上下文中的下一个词(token)。这是一种序列建模任务,可以通过循环神经网络(RNN)、长短时记忆网络(LSTM)或 Transformer 等 NLP 技术来实现。
- 自注意力机制:自注意力机制是一种在NLP领域中发展起来的技术,它允许模型关注输入序列中与当前 token 相关的其他 tokens。这种机制在大型语言模型(如基于 Transformer 的 GPT 系列模型)中得到了广泛应用,以提高模型对上下文的理解能力。
- 迁移学习:在 NLP 领域,迁移学习是一种将在一个任务上学到的知识应用于另一个任务的方法。大型语言模型采用预训练-微调的框架,即在大量无标签文本数据上进行预训练,然后在特定任务上进行微调。这种迁移学习方法使得大型语言模型能够在各种 NLP 任务上表现出卓越的性能。
- 生成和解码技术:在生成自然语言文本时,大型语言模型和 NLP 共享相同的解码技术,如贪婪搜索、束搜索或采样。这些技术可以生成高质量、连贯的自然语言文本,并确保模型在不同任务中具有良好的生成性能。
- 多任务学习:NLP 领域的多任务学习方法被用于训练大型语言模型以解决多个任务。例如,T5(Text-to-Text Transfer Transformer)模型将各种 NLP 任务统一为一个文本到文本的转换问题。通过这种方法,大型语言模型可以在单一框架下处理多种任务,提高资源利用率和性能。
- 对抗训练与正则化:NLP 领域的对抗训练和正则化技术也应用于大型语言模型。例如,对抗训练可以增加模型的鲁棒性,使模型对抗性样本的性能更佳;正则化方法(如权重衰减、Dropout等)可以降低模型复杂度,防止过拟合,提高泛化能力。
- 知识蒸馏:知识蒸馏是一种在 NLP 领域发展起来的模型压缩技术。它可以将大型语言模型的知识迁移到一个较小的模型中,以降低计算和存储需求。这种方法使得大型语言模型能够在资源受限的环境下应用,如移动设备或边缘计算。
- 低资源语言适应:大型语言模型和NLP领域也关注如何处理低资源语言。为了支持这些语言,研究人员尝试将模型从高资源语言迁移到低资源语言,例如使用多语言模型、跨语言迁移学习或元学习等方法。这有助于使大型语言模型在多种语言环境中具有更广泛的适用性。
DL 与 LLMs 的关系如下:
- 神经网络结构:大型语言模型通常基于深度神经网络,这些网络可能包括多层感知机(MLP)、循环神经网络(RNN)、长短时记忆网络(LSTM)或 Transformer 等结构。这些神经网络结构为大型语言模型提供了基础框架,使其能够在多层次上表示和理解自然语言数据。
- 参数学习:深度学习模型通过优化大量的参数来学习从输入到输出的映射关系。大型语言模型也同样依赖于参数学习,它们通常具有数亿甚至数千亿的参数,这些参数在训练过程中不断更新以捕获自然语言的复杂性和多样性。
- 激活函数与层间连接:深度学习模型中的激活函数(如 ReLU、tanh 等)以及层间连接(如全连接、卷积、自注意力等)在大型语言模型中同样发挥作用。这些组件为模型提供了非线性和上下文信息处理能力,使模型能够捕获更复杂的语言规律和特征。
- 反向传播与优化算法:大型语言模型的训练过程通常依赖于深度学习中的反向传播算法,用于计算梯度并更新模型参数。同时,优化算法(如梯度下降、Adam 等)也在大型语言模型的训练中发挥作用,以提高模型收敛速度和性能。
- 损失函数:在深度学习中,损失函数度量模型预测与真实标签之间的差异。大型语言模型也采用类似的损失函数(如交叉熵损失)来评估模型在训练过程中的表现,以指导模型参数的更新。
- 预训练与微调策略:深度学习领域的预训练和微调策略在大型语言模型中得到了广泛应用。这些策略允许模型在无标签数据上进行预训练,然后在特定任务的标签数据上进行微调,从而实现有效的迁移学习和泛化能力。
- 正则化与模型压缩:深度学习中的正则化技术(如权重衰减、Dropout 等)和模型压缩方法(如知识蒸馏、网络剪枝等)在大型语言模型中同样有应用。这些方法可以降低模型复杂度,防止过拟合,提高泛化能力;同时,通过模型压缩,可以降低大型语言模型的计算和存储需求,使其在资源受限的环境下更易部署和使用。
- 数据增强:在深度学习中,数据增强是一种通过对训练数据进行扰动、变换等操作以扩充数据集的方法。在大型语言模型的训练中,类似的数据增强方法(如文本重写、掩码语言建模等)也可以帮助模型学习更丰富的语言表示,从而提高模型在各种 NLP 任务中的性能。
- 可解释性与可视化:深度学习领域的可解释性和可视化技术在大型语言模型中同样具有重要价值。例如,可视化注意力权重可以帮助我们理解模型在处理自然语言时如何关注输入序列中的不同部分,从而提高模型的可解释性和可靠性。
- 强化学习与序列决策:在某些场景下,大型语言模型可能会结合深度强化学习技术进行训练。这类方法通常包括学习策略、探索、奖励函数等,使模型在面对复杂的序列决策问题时能够找到最优解决方案。